Pentaho(ペンタホ)のETLツール、Kettle(ケトル)のPan(パン)には、Row Denormaliser(行非正規化)というトランスフォーメーションのステップがあります。本日、使い方を理解できたので、ここに記録しておきたいと思います。
参考:http://wiki.pentaho.com/display/EAI/Row+De-normalizer
Row Denormaliser(行非正規化)とは

Row Denormaliserは、1列に納まっているデータを複数列に分割するステップです。正規化されているデータを非正規化します。
例えば、次のようなイメージのDBテーブルとデータがあったとします。
| 取引先ID | 取引先属性 | 取引先属性値 |
| 取引先001 | 好きな食べ物 | ケーキ |
| 取引先001 | 誕生日 | 1975/10/10 |
| 取引先002 | その他の属性 | 12345 |
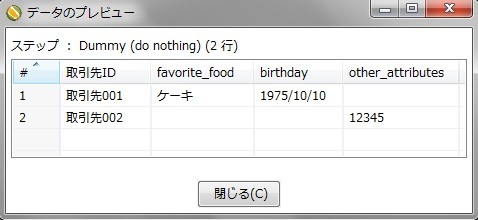
このようなデータを取引先IDのデータをキーとして、取引先属性のデータをカラムにして、そのカラムの値を取引先属性値のデータにする事ができます。
| 取引先ID | favorite_food | birthday | other_attributes |
| 取引先001 | ケーキ | 1975/10/10 | null |
| 取引先002 | null | null | 12345 |
Row Denormaliserの使い方

データグリッドステップで、先の例と同じデータを作成します。


- ステップ名…ステップの名称を入力します。
- フィールド名(キー値)…複数列に分割する列(フィールド)を選択します。
【フィールド(グループ)】
- フィールド名…データをグルーピングし、Row Denormaliser後のキーフィールドとなるフィールドを設定します。
【フィールド(出力先)】
- フィールド名(出力先)…Row Denormaliser後に作成されるフィールドを定義します。
- フィールド名(参照元)…上記で作成したフィールドに入力したい値を持つ列(フィールド)を設定します。
- キー値…"フィールド名(キー値)"に設定した列(フィールド)に実際に入力されている値を設定します。ここで設定した値があった時に、その"フィールド名(参照元)"フィールドに設定されている値が、Row Denormaliser後に"フィールド名(出力先)"の値に代入されます。
次のような結果になります。